Siggraph Asia 2024渲染论文速递
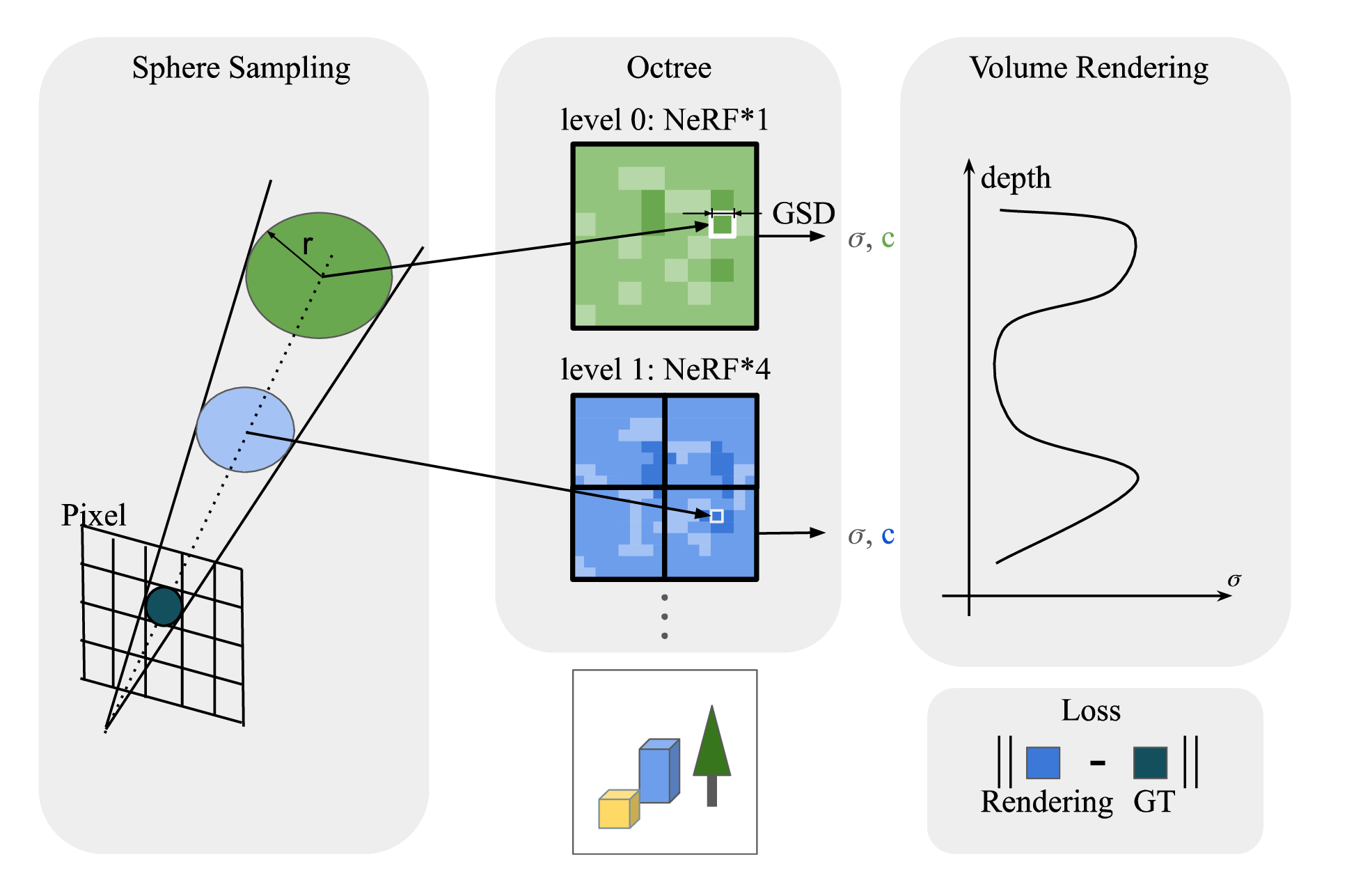
InfNeRF: Towards Infinite Scale NeRF Rendering with O(log n) Space Complexity
用八叉树给 NeRF +NGP 叠上了八叉树,每个八叉树节点再用 2048 的 NGP Nerf,不懂 NeRF,但是看起来像 A+B 的工作

GS^3: Efficient Relighting with Triple Gaussian Splatting
吴鸿智老师组的工作,给 3d gaussian 引入了更复杂的参数,把着色拆分成 Lambertian+angular gaussian(又进一步 PBR 化了),再把单光源的阴影拆出来。看起来能处理的材质复杂度就高了很多,毛发什么的表现也不错,可惜似乎只支持单光源。 代码开源在 https://github.com/gsrelight/gs-relight

MARS: Multi-sample Allocation through Russian roulette and Splitting
Adaptive multi-sample MIS,在之前的方法(只优化 variance)上额外考虑 sample 的 cost(实际上最后是优化一个分段的 proxy),基于不动点迭代来分配每个 vertex 的 MIS 样本数,这样可以一定程度上提升时间效率。但是实际结果提升有限,RRS 真是要被卷烂了。

Efficient Neural Path Guiding with 4D Modeling

Dynamic Neural Radiosity with Multi-grid Decomposition
都是北大李胜老师组的工作,思路很像就一起了,都是用 Sparse Grid 来做高维输入(前者加了一个 t,后者加了一些可编辑的参数),使得大伙能做动态场景了。但是后者看起来本质上是在 Neural radiosity 上提出一些编码整的活(频率编码、SH 编码方向),速度还是受限于场景的可变参数,PG 不是很懂不予置评。NGP 真是无敌啊,把整个神经渲染编码盘起来了。

Neural Global Illumination via Superposed Deformable Feature Fields
浙大霍宇驰老师组的神经渲染工作,在 NeLT 的基础上加上了可变形的 NGP +triplane 编码来实现更好的空间特征映射,并且用多个物体并行编码的方式把 encode 的速度提上去了,效果还是很 fancy 的。可惜的是最后还是接的一个大 decoder,而且并行化编码比较玄学,GPU 要是吃满了也只能老老实实串行了,场景能动的物体一多帧率也还是会往下掉不少。

End-to-End Hybrid Refractive-Diffractive Lens Design with Differentiable Ray-Wave Model
折射-衍射的 ray-wave 模型可微化,使得透镜的优化可以端到端化,很有意思的基石性工作。不过看起来对比先前工作提升的主要是精确性,希望有朝一日这样的工作能拯救我没对上焦的照片(x)

A Statistical Approach to Monte Carlo Denoising
这个年代能看到 neural-free 的 denoiser 确实不容易啊,核心是提出了一种基于 Welch t-test 的采样策略,用来接收/拒绝临近像素样本做 denoise。但是缺点也很明显,统计方法是需要优秀样本来辅助的,在低 spp 的情况下还是打不过一众 neural denoiser,而且似乎这个方法是需要输入像素所有 MC 样本的,导致实用性进一步下降。

Hierarchical Light Sampling with Accurate Spherical Gaussian Lighting
AMD 关于 manylight 的工作,在 stochastic lightcut 的基础上把树的节点用 SG 表示来得到更紧凑的表达,用 NDF 过滤来保证 MC 采样的无偏性。可以和 ReSTIR 结合起来用生成更好的样本,看了下 Reddit 上有人实现的给了好评,不过树还是得在 CPU 上建,Lightcuts 这一类方法感觉还是不太 GPU 友好。

A Dynamic By-example BTF Synthesis Scheme
闫令琪老师组的工作,熟悉的材料啊。把 BTF 的 6D 分解成两张 2D 方向纹理,再把 position 作为一个编码参数总共三张(原文里称为 triple plane),在运行时用 MLP 动态合成 BTF,但是似乎 MLP 还是 per material per train 的,让人不禁想问引入这三张纹理的意义(不懂,求指正)。
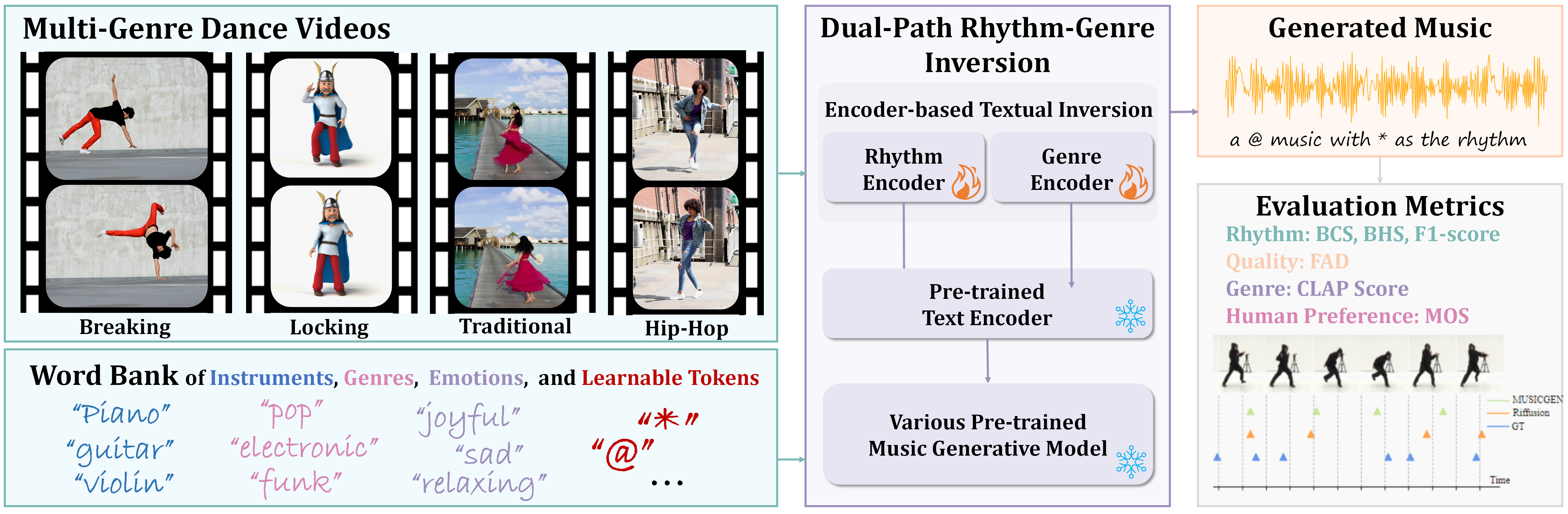
Dance-to-Music Generation with Encoder-based Textual Inversion
不是渲染,但是看起来很有意思,从跳的舞蹈里提取 text prompt 来指导音乐合成,开源在 lsfhuihuiff/Dance-to-music_Siggraph_Asia_2024: The official code for “Dance-to-Music Generation with Encoder-based Textual Inversion“。似乎用的是固定 prompt a @ music with * as the rhythm,那大概考虑不到舞蹈过程中的节奏变换:-(
Siggraph Asia 2024渲染论文速递
https://hyiker.github.io/2024/12/26/Siggraph-Asia-2024渲染论文速递/