本文记录一个菜鸡完整的在Blender中创建布料动画并导出为glTF/USD格式的过程,作为笔记供后续查阅。
创建布料动画
本部分完全参考Gemini给出的流程(不得不说Gemini已经强到可以教人用Blender的程度了):
在Blender中制作“风吹晾衣绳上的床单”是布料模拟(Cloth Simulation)的一个经典案例。这涉及到三个核心环节:布料设置(Cloth)、固定点(Pinning)和风力场(Wind Force Field)。
以下是详细的分步教程:
本文记录一个菜鸡完整的在Blender中创建布料动画并导出为glTF/USD格式的过程,作为笔记供后续查阅。
本部分完全参考Gemini给出的流程(不得不说Gemini已经强到可以教人用Blender的程度了):
在Blender中制作“风吹晾衣绳上的床单”是布料模拟(Cloth Simulation)的一个经典案例。这涉及到三个核心环节:布料设置(Cloth)、固定点(Pinning)和风力场(Wind Force Field)。
以下是详细的分步教程:
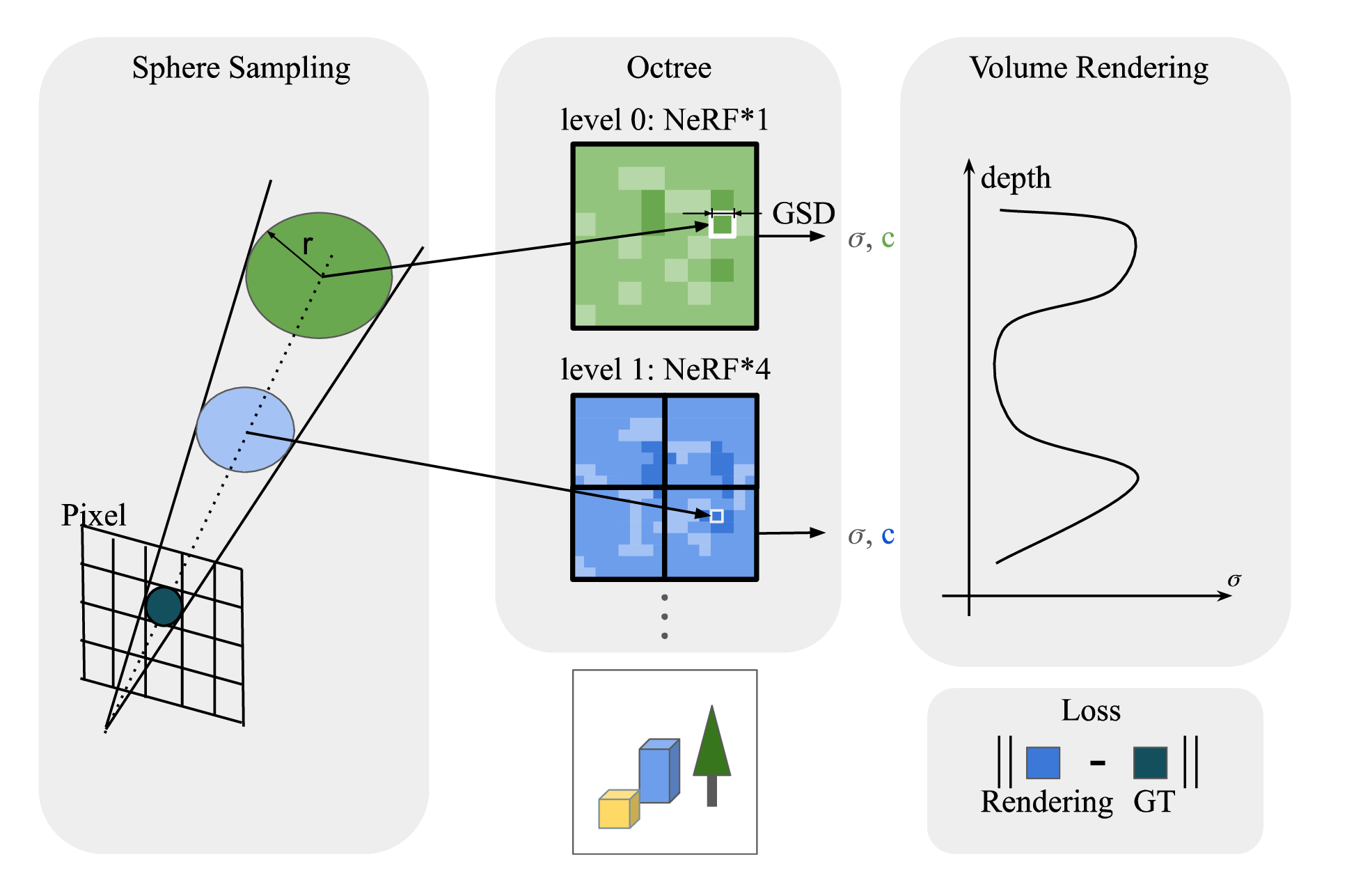
InfNeRF: Towards Infinite Scale NeRF Rendering with O(log n) Space Complexity
用八叉树给 NeRF +NGP 叠上了八叉树,每个八叉树节点再用 2048 的 NGP Nerf,不懂 NeRF,但是看起来像 A+B 的工作

GS^3: Efficient Relighting with Triple Gaussian Splatting
Where \(\mathbf K\) is the local scattering operator, \(L_o = \mathbf K L_i\), both \(L\) defined in the whole ray space \(\mathcal R\):
\[ (\mathbf Kh)(\mathbf{x}, \omega_o) = \int_{S^2} f_s(\mathbf{x}, \omega_i \to \omega_o) \, h(\mathbf{x}, \omega_i) \, d\sigma_{\mathbf{x}}^\perp(\omega_i) \] \(\mathbf G\) is the propagation operator, defining the geometric property of the space, \(L_i = \mathbf G L_o\), which should be symmetric. \[ (\mathbf Gh)(\mathbf{x}, \omega_i) = \begin{cases} h(\mathbf{x}_M(\mathbf{x}, \omega_i), -\omega_i) & \text{if } d_M(\mathbf{x}, \omega_i) < \infty, \\ 0 & \text{otherwise,} \end{cases} \]
Now right the light transport equation in operator form: \[ L = L_e + \mathbf T L \] Inverting the operator equation: \[ \begin{equation} \begin{aligned} (\mathbf I - \mathbf T)L &= L_e \\ L &= (\mathbf I - \mathbf T)^{-1} L_e \end{aligned} \end{equation} \] Defining solution \(\mathbf S = (\mathbf I - \mathbf T)^{-1}\). Given that \(\Vert \mathbf T \Vert \lt 1\), the inversion can be expanded with Neumann series: \[ \mathbf S = (\mathbf I - \mathbf T)^{-1} = \sum^{\infty}_{i = 0} \mathbf T^i = \mathbf I + \mathbf T + \mathbf T^2+ \cdots \] Light transport can then be expanded as well: \[ L = L_e + \mathbf T L_e + \mathbf T^2 L_e + \cdots \tag{2} \]
最近在学习写一个离线渲染器的时候,有一个需求是要实时地追踪一条射线逐个打到的物体然后显示debug信息的功能(顺便一说,这个功能真的很好用也很好玩),离线部分仿照的pbrt-v3,交互的前端则是使用的imgui+OpenGL。前面的实现都很顺利,但是到渲染车辆场景的时候,发现射线没有做到指哪打哪,那肯定是出问题了,于是我从头到尾地排查了一遍所有的变换相关的代码。发现了两个问题:
perspective矩阵变换的Z范围为\([0, 1]\)。进行排查的同时也系统化地解决了大量疑问:
MVP矩阵到底是在哪些空间中进行变换?fiber 纤维,股的组成部分 ply 股(织线的组成) yarn 纺线,n-ply yarn,n股纺线 - ply level 由ply不同的数量、缠绕的方式造成的yarn的不同外观 woven cloth 梭织 - warp-weft 经-纬 knitted cloth 针织 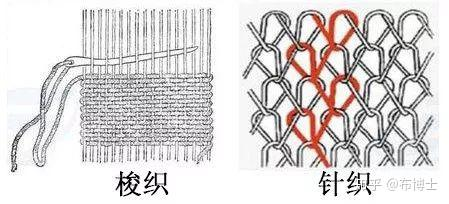 - knittet coth 会由于缠绕方式的不同产生体积/阴影遮挡效果,这个层级被称为pattern level
- knittet coth 会由于缠绕方式的不同产生体积/阴影遮挡效果,这个层级被称为pattern level
首先摘抄一段wiki上对于Perlin噪声的介绍:
Perlin噪声(Perlin noise)指由Ken Perlin发明的自然噪声生成算法。由于Perlin本人的失误,Perlin噪声这个名词现在被同时用于指代两种有一定联系的的噪声生成算法。这两种算法都广泛地应用于计算机图形学,因此人们对这两种算法的称呼存在一定误解。下文中的Simplex噪声和分形噪声都曾在严肃学术论文中被单独的称作Perlin噪声。
接下来,我将围绕生成一张2D噪声纹理为目标展开对于几种噪声生成方法的介绍。
为什么我们需要这两种新的噪声生成方法?对于噪声的生成方法,最为平凡的办法当然是对于每个点取一个均匀分布的随机数,如,生成一个\([0,1]\)的uniform随机数,然后直接将其作为灰度值使用:
/blender_bssrdf.jpeg)
PBR论文简读:Better BSSRDF Models(1)
在上一篇简读论文:PBR论文简读:A Practical Model for Subsurface Light Transport(后文将以Basic BSSRDF模型来指代本文提出的模型)提出BSSRDF模型后,人们陆陆续续发现了模型中的很多不足与需要改进的地方,因此接下来几篇blog将会简读几篇关于Basic BSSRDF模型的改进方法相关的论文。
这篇论文主要指出了Basic BSSRDF中没有考虑到薄介质、多层、粗糙接触面的非理想情形下的问题,提出了多层(Multi-Layered)的BSSRDF模型。

PBR论文简读:A Practical Model for Subsurface Light Transport
离线环境下进行真实感渲染的时候,会有各种散射材质,比如人类皮肤、硅胶等。从外观上看,这类材质的通性在于都有一种“透光”的感觉,简单的使用brdf创造出来的材质往往显得很生硬,因此Jensen'01的这篇论文给出了一个实际的次表面散射(subsurface scattering)bxdf来实现这种材质。
BRDF理论假设材质光的进入和离开的起、终点一致,本质上是对BSSRDF的一种近似\(x_o = x_i\),并且给出的积分公式也是简单地在半球面上进行积分,BSSRDF则考虑的是出、入射点不同时,对于区域\(A\)内所有入射光线的radiance的半球面积分:
\[L_o = \int_A\int_{2\pi}S\cdot L_i\cdot (\vec n\cdot \vec {\omega_i})d\omega_i dA(x_i)\]
先上个成果图:
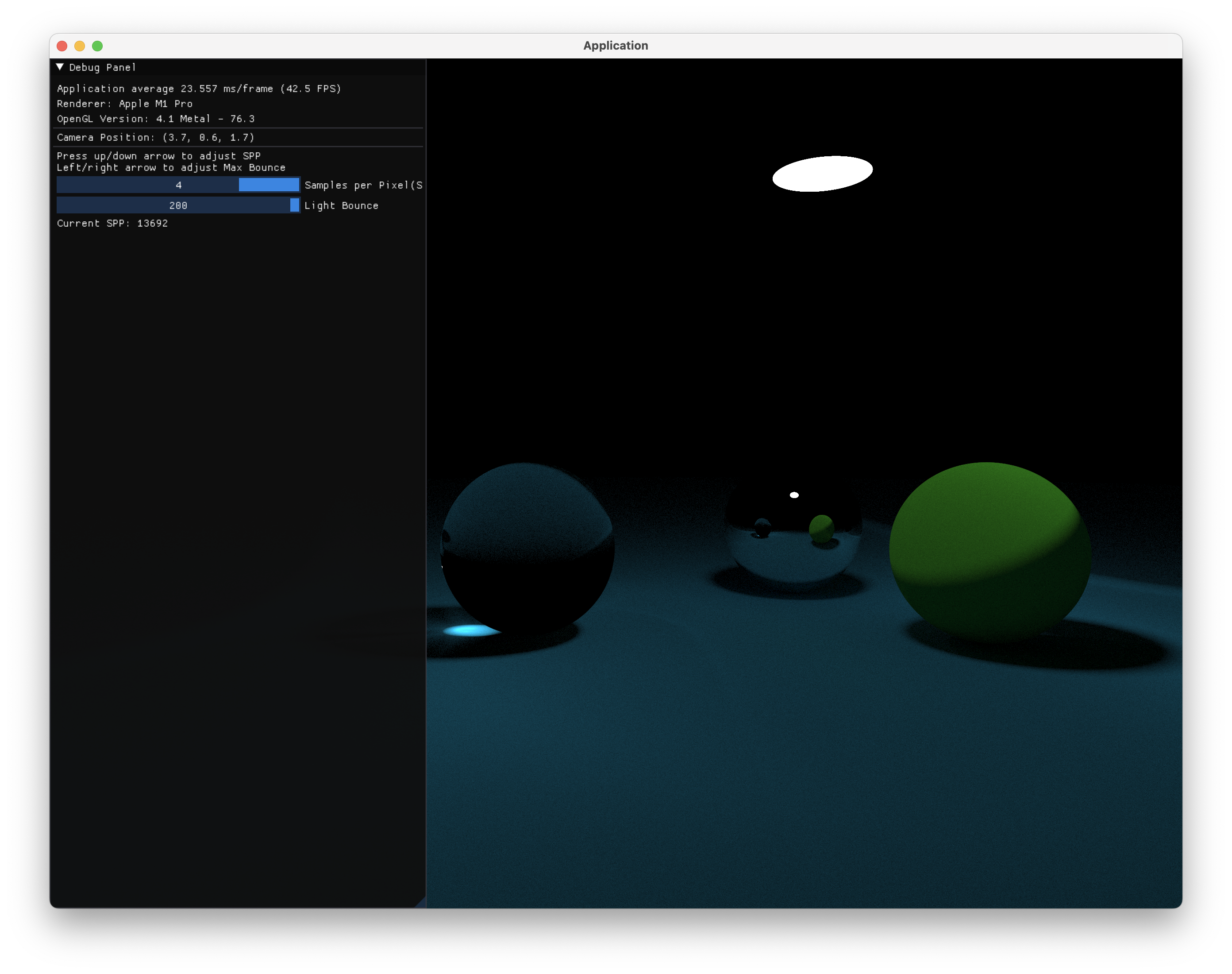
使用OpenGL和GLSL实现了一个基于物理的蒙特卡洛路径追踪,接下来简述一下实现的原理和思路。仓库地址:RealtimeRayTracing
在OpenGL端,采用了简单的ping-pong texture和一个final shading来实现了逐帧增加spp数量的效果:
从上次面试之后,就寻思着用Unity做一些实时的渲染效果,这个时候就想起了GAMES202作业中的实时屏幕空间反射。
屏幕空间反射效果可以产生微妙的反射,模拟潮湿的地板表面或水坑。这种技术产生的反射质量低于使用反射探针或平面反射(后者可以产生完美平滑的反射)。屏幕空间反射是用于限制镜面反射光泄漏量的理想效果。
屏幕空间反射的本质是利用GBuffer中的Normal, Albedo, Depth几个分量进行屏幕空间(以及view space)的RayMarching,简单的做法是,从摄像机发射一条光线到每个Shader fragment,再根据fragment的法线计算出reflect方向,这样就相当于得到了一条ray的origin和dir。这个时候我们再将步进的射线的z深度与depth texture的值进行比较,即可得到是否intersect,进而进行反射颜色的计算。
首先给Unity的摄像机加上一个material和shader,用类似于opengl的blit方法将渲染目标更改为一个texture传输给shader,这里因为Unity好像没有提供WorldToView矩阵,我们需要自己传给Shader,同时由于需要使用GBuffer中的信息,需要将渲染模式改为deferred(其实也不是必须的,但是使用前向渲染模式需要自己手动额外渲染所需的信息,会造成资源的浪费)。