FastAPI部署PyTorch CPU inference项目内存泄漏以及解决方案
起因
最近需要在一个2c4g的一个服务器上做VITS-fast-finetuning项目的边缘部署,VITS算一个不大不小的模型,实测下来服务器的内存只有3.6G,刨开乱七八糟的服务也就只剩下少得可怜的2G左右内存可用,因此需要相当地精打细算才能得到比较好的效果。
前端没啥好说的,自己和copilot合作了一下撸了一个又不是不能用的,之后就轮到重量级的后端登场了。
还在漏还在漏
首先我们的需求和一些现实情况如下:
- 服务器的内存和CPU资源都相当吃紧,基本每一次TTS请求都能把两核的CPU吃满
- 我希望每一次请求响应都够快,最简单的解决办法就是对模型(tts_fn)进行caching,相应的需要trade off一些内存
- 根据上一条需求,我们最好不要用subprocess来进行模型的推理,即使不考虑subprocess本身的开销,我们也不希望每一次请求都要重新加载模型
需求对应的代码其实很简单,但是最后我使用Gunicorn + Uvicorn worker + FastAPI进行部署的时候出问题了:我手上有5个模型,但是只要请求数一多,整个服务器就会直接死掉,这是怎么会事呢?
首先我们刨掉几个模型,剩下三个,然后把worker给减到一个。发现运行几次之后,内存占用不停增长,直到把3.6G全部吃满,服务器没有响应,连SSH都会卡死(这里建议不要急,等个几分钟操作系统就会直接把内存清理掉)。
问题定位
首先我们假设内存泄漏不出在VITS-fast-finetuning身上(实际上我检查了一遍也确实没有),一般来说简单的python web代码也没法写出内存泄漏的问题。使用开箱即用的memory_profiler进行内存分析:这个库提供了非常方便的memory_profiler.profile装饰器,可以直接在函数上使用,然后就可以得到函数单步的内存占用情况。
给每一个有嫌疑的函数都打上了@profile,发现问题出在了一个卷积层Conv1D上(偷懒图里不是同一次请求的调用栈,不过无伤大雅):
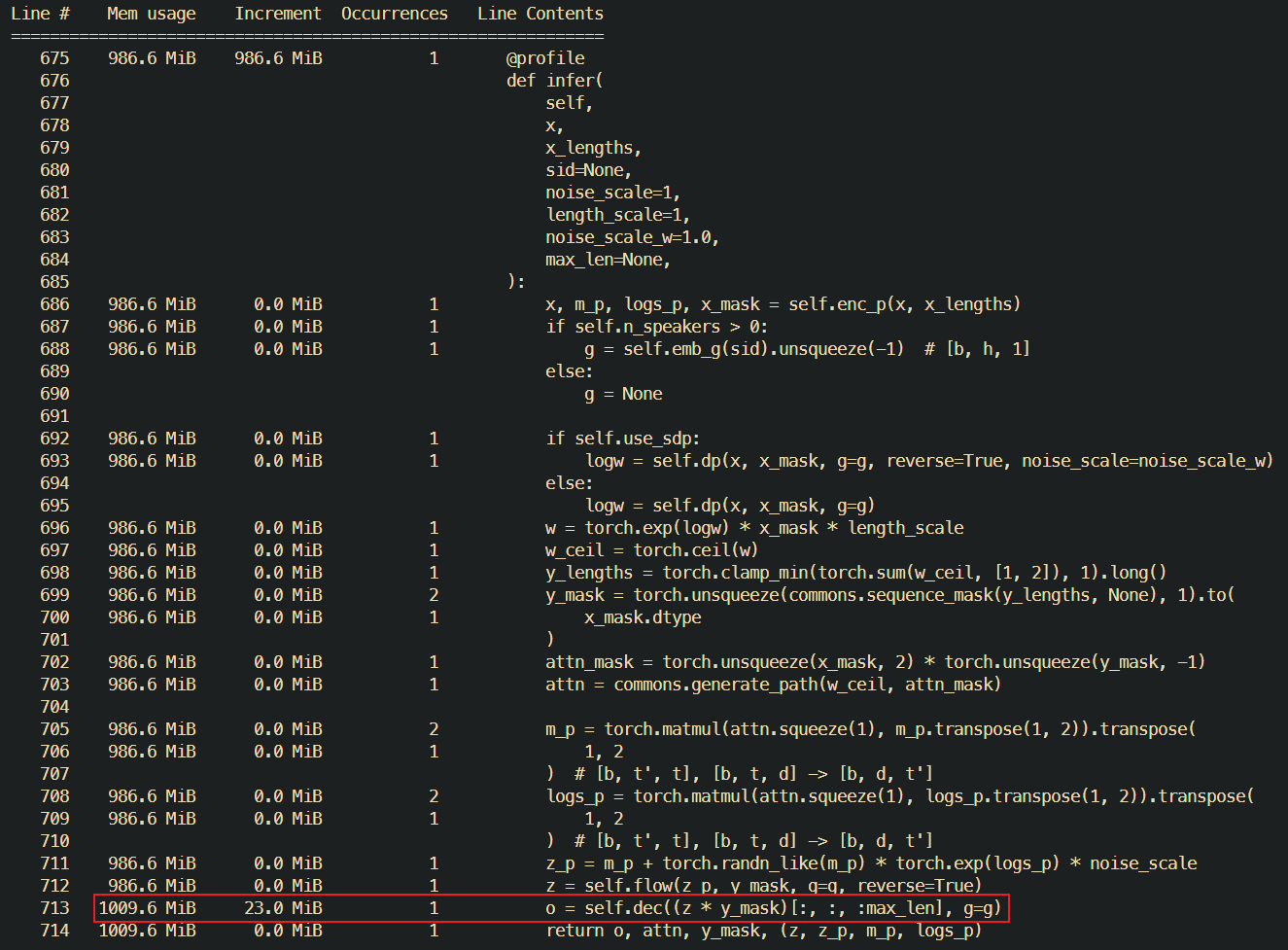
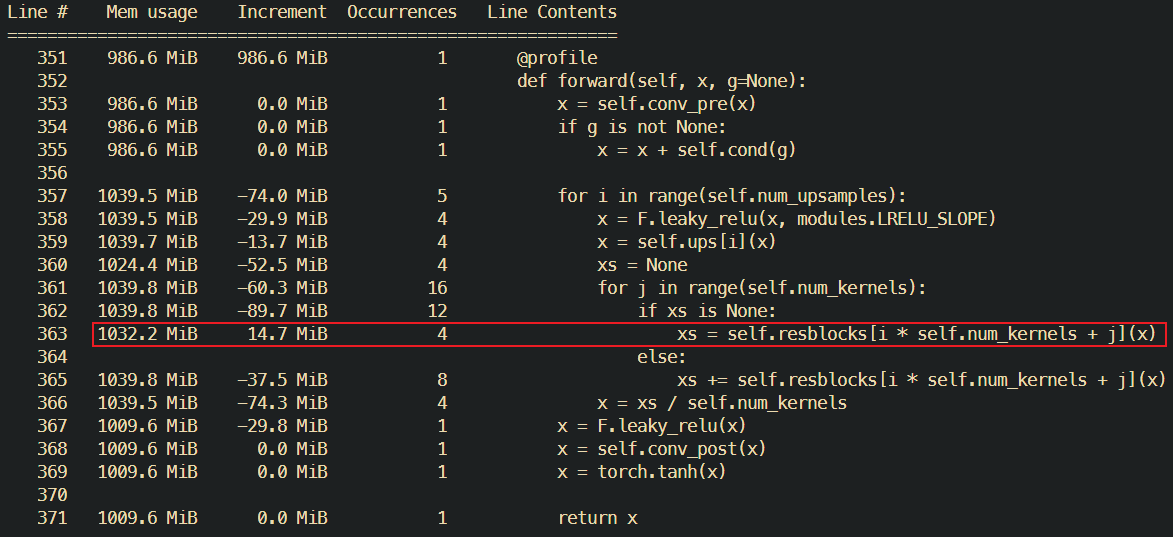
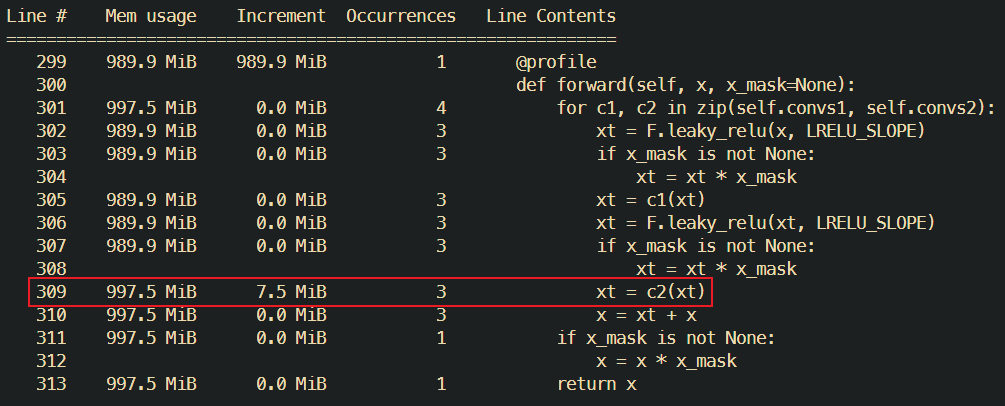
每个卷积层每次调用都会增加15-30M左右的内存占用,不幸的是模型中对该卷积层进行了循环调用,每一次请求下来整个服务器内存占用都会增加10M左右,在htop中查看也基本一致。
漏水容易补水难
在进行profile之前我先上网搜了一下FastAPI+Pytorch+内存泄漏相关的问题,得到的答案无非是:
- 这是worker内存的问题,使用
async进行异步处理:实测对于我的问题没有任何帮助 - 使用
subprocess进行模型推理:不符合需求,pass - 使用
jemalloc替代glibc:具体的方法是安装jemalloc并手动指定环境变量LD_PRELOAD=LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libjemalloc.so.2,根据测试可以大幅减少内存的占用(在加载一个模型的时候总内存占用从3G+降低到了2.6G+左右),但是随着请求的增加,内存占用还是会不断增加,pass
解决方案
Damn, who knows! 在发现问题出在卷积层后,找到了这个issue:Memory leak in Conv1d,就是这个!这个issue在23年9月提出&&解决了,但是看样子服务器上的pytorch并没有实装这个fix,但是一个回复中提到了一个解决方案:
When our validation team tried to reproduce it on CPU, all the to('cuda') has been changed to to('cpu'). As it is a case with dynamic shape inputs, the primitive and primitive description cache has made the memory increase at the beginning when it hasn't reached the maximum cache capacity size. By setting the below environment variables to decrease the cache capacity, the memory won't increase anymore: ONEDNN_PRIMITIVE_CACHE_CAPACITY=0 LRU_CACHE_CAPACITY=1
设置这两个环境变量之后,内存占用果然不再增加,翻译成人话就是:
在动态shape的输入下,pytorch会缓存一些东西,primitive和primitive缓存会在未达到最大缓存大小的时候不断增加,通过设置这两个环境变量可以减少缓存的容量,使得内存占用不再增加直到服务器死掉。
Gunicorn:哈哈,没想到吧
这个办法对于Uvicorn直接运行是生效的,但是我在服务器上直接跑了一个systemd service的gunicorn,前面说的东西在这玩意上一用上好像diao用没有,这是怎么会事呢?
探查后发现Gunicorn似乎不会老实地把自己的环境变量传递给worker子进程,需要在配置文件中手动指定:
1 | raw_env = ["ONEDNN_PRIMITIVE_CACHE_CAPACITY=0", "LRU_CACHE_CAPACITY=1", "LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libjemalloc.so.2"] |
And finally, its works fine.
省流总结
设置环境变量ONEDNN_PRIMITIVE_CACHE_CAPACITY=0和LRU_CACHE_CAPACITY=1,可以减少pytorch的缓存容量,避免内存泄漏(伪),此外推荐使用jemalloc替代glibc,可以减少内存占用。
FastAPI部署PyTorch CPU inference项目内存泄漏以及解决方案
https://hyiker.github.io/2024/02/14/FastAPI部署PyTorch-CPU-inference项目内存泄漏以及解决方案/